
Anvil impact highlighted in National Artificial Intelligence Research Resource Pilot webinar
Dr. Haniye Kashgarani, a Senior AI Scientist at the Rosen Center for Advanced Computing (RCAC), recently gave a presentation for the NAIRR Pilot Partner Series Webinar. Her presentation focused on how Anvil, one of Purdue University's most powerful supercomputers, is helping researchers across the country to tackle scalable, data-intensive AI workloads.
Anvil is  an National Science Foundation (NSF)-funded system that provides researchers from diverse backgrounds with advanced computing capabilities. In 2024, Anvil became an official resource provider for the newly launched National Artificial Intelligence Research Resource (NAIRR) Pilot project. This is a pilot version of a project aimed at creating a national infrastructure that connects U.S. researchers to responsible and trustworthy Artificial Intelligence (AI) resources. The NAIRR project will also provide these researchers equitable access to the data, software, training, computational, and educational resources needed to advance research, discovery, and innovation within the field of AI. In order to fully support the NAIRR Pilot, Anvil received supplementary funding from the NSF. This funding enabled RCAC to develop “Anvil AI,” an additional Anvil partition with advanced graphics processing units (GPU) that are needed for AI workloads. A total of 84 Nvidia H100 SXM GPUs were procured and added to the system. Once the expansion was installed, Anvil was ready to take on NAIRR research projects and support the nation’s AI capabilities.
an National Science Foundation (NSF)-funded system that provides researchers from diverse backgrounds with advanced computing capabilities. In 2024, Anvil became an official resource provider for the newly launched National Artificial Intelligence Research Resource (NAIRR) Pilot project. This is a pilot version of a project aimed at creating a national infrastructure that connects U.S. researchers to responsible and trustworthy Artificial Intelligence (AI) resources. The NAIRR project will also provide these researchers equitable access to the data, software, training, computational, and educational resources needed to advance research, discovery, and innovation within the field of AI. In order to fully support the NAIRR Pilot, Anvil received supplementary funding from the NSF. This funding enabled RCAC to develop “Anvil AI,” an additional Anvil partition with advanced graphics processing units (GPU) that are needed for AI workloads. A total of 84 Nvidia H100 SXM GPUs were procured and added to the system. Once the expansion was installed, Anvil was ready to take on NAIRR research projects and support the nation’s AI capabilities.
Kashgarani’s presentation began with an overview of the Anvil system, the traditional allocation system for utilizing Anvil (the NSF’s Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support [ACCESS], a program that serves tens of thousands of researchers across the United States), and the new NAIRR allocation system. She also discussed how the NAIRR supplemental funding has supported Anvil via hardware upgrades and dedicated AI research scientists who can provide support to researchers using the system. Kashgarani continued the Anvil overview by highlighting scientific applications that are available on the Anvil system, including bioinformatics, computational chemistry, engineering, climate science, and AI software, as well as discussing the newly developed AnvilGPT, a large language model (LLM) service that that researchers worldwide can easily access and use. AnvilGPT is hosted and supported entirely on-premises at Purdue and no uploaded documents or queries are used for training, which negates the concern of leaking intellectual property or proprietary data.
One notable computational capability that Anvil provides to NAIRR is a composable infrastructure. The Anvil Composable Subsystem is a Kubernetes-based private cloud managed with Rancher that provides a platform for creating composable infrastructure on demand. This cloud-style flexibility allows researchers to self-deploy and manage persistent services to complement HPC workflows and run container-based data analysis tools and applications. The composable subsystem is intended for non-traditional workloads, such as science gateways and databases, and the recent addition of composable GPU nodes supports tasks such as AI inference services and model hosting, a major boon for NAIRR researchers. Kashgarani noted in her presentation that the Anvil Composable setup makes it easy for researchers to launch and manage services, get feedback, and make updates to the applications and the services that they want to make available publicly.
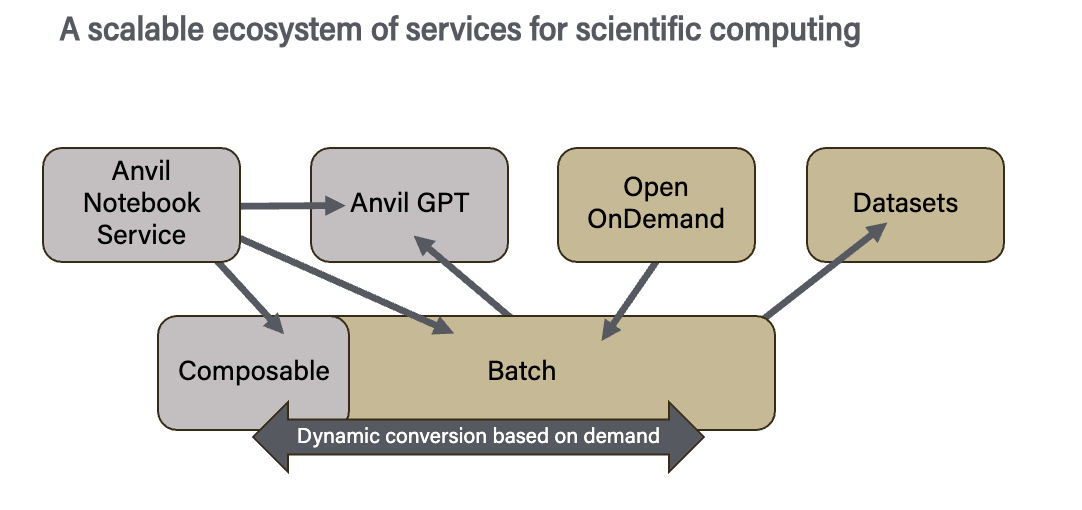
Another boon for NAIRR researchers that Anvil provides is the availability of a wide range of popular, domain-specific datasets. These datasets are hosted on the Anvil system and made available as modules, which can be easily loaded and added to workflows. To improve ease-of-use for the datasets, the Anvil team developed a conversational search made available through the dataset query. This enables a context-sensitive chat function that summarizes information from various dataset documents and works across multiple domains. Researchers can utilize this function to easily identify which datasets would be best for their specific work. Examples of these datasets include:
- Genomes: A collection of reference sequences and annotation files for 38 commonly analyzed organisms.
- GOES-16: Nearly 10TB of GOES-16 datasets. This dataset is currently being used to train AI models for improved weather forecasting.
- NOAA AORC: 31TB of NOAA Analysis of Record for Calibration (AORC) dataset. AORC Forcing data includes the years 1979-2021.
- NCBI Blast: NCBI Blast databases to support the life sciences community. This continues to be mirrored and updated.
- Eggnog mapper: EggNOG-mapper, a tool for function annotation of biological sequences, relies on precomputed databases of evolutionary relationships to annotate novel genomes, transcriptomes, or metagenomes.
Next, Kashgarani discussed Anvil’s User Support and Training services. Anvil offers a tiered user support structure. Tier 1 handles triage and first responses, while Tier 2 and Tier 3 brings domain expertise when needed. NAIRR researchers can utilize this structure by submitting support tickets. For quick questions or a more informal setting, the Anvil team also offers regular Anvil support hours. These are dedicated sessions each week where users can “drop in” (virtually) and get one-on-one live feedback from one of the Anvil support staff. As for training, the Anvil team offers a number of options for users of all experience levels, both in asynchronous and live, lecture-style formats.
To wrap up the webinar, Kashgarani highlighted some of the current NAIRR research projects that are being conducted on Anvil. The three examples she showcased were:
-
Transforming 3D Object Detection for Safer Self-Driving: Using Anvil AI resources, researchers at Cornell developed a novel autoregressive model for 3D bounding box prediction, enabling robust detection under occlusion.
-
Advancing Epilepsy Diagnosis with LLMs: On Anvil GPU, Stevens Institute researchers curated and processed seizure data for patients, developing a language-model-based tool to identify epileptogenic zones from clinical descriptions—accelerating clinical insights.
-
Personalizing Mask Design Through Dynamic Speech Modeling: Leveraging Anvil GPU, FAMU-FSU researchers simulated real-time mask leakage during speech, revealing gender-based leakage patterns and informing design improvements for public health protection.
Kashgarani’s webinar presentation was well received. At the time of the presentation, Anvil had 31 active NAIRR projects led by a total 105 unique researchers. The webinar certainly sparked interest and several Principal Investigators reached out to submit proposals after the event. Now Anvil has 34 active NAIRR projects with 115 unique researchers, with more and more inquiring about the allocation process each week. To view Kashgarani’s presentation in its entirety, please visit: NAIRR Pilot Partner Series Webinar
Researchers and educators can apply for access to NAIRR resources and view descriptions of NAIRR projects at https://nairrpilot.org/. Resource request submissions can be made following the process outlined in https://nairrpilot.org/opportunities/allocations. Submissions should select “Purdue Anvil CPU” or “Purdue Anvil GPU” as the preferred resource, depending on the user’s needs. Anyone with questions should contact anvil@purdue.edu.
More information about Anvil is available on Purdue’s Anvil website. Anvil is funded under NSF award No. 2005632.
Written by: Jonathan Poole, poole43@purdue.edu